We will be posting results based on SignalSolver sentiment and tracking them (paper trading them) moving forward. The purpose of this article is to explain how those results are arrived at. The postings will have two charts and a table to describe the results of the simulations and also a pdf file describing the Settings within SignalSolver if you have a desire to set up the system for yourself and try to tweak it.
The sentiment indicator is calculated using backtesting but Sentiment runs are not backtests. They are walk-forward, out-of-sample simulations, as we shall explain.
Bullish percentage
For any given trading day, we typically backtest 250 days of price data ending on the day in question using over 100 algorithms (pre-selected from about 400,000) and sort those algorithms based on performance. We now look at the top N algorithms, where N is typically 10 to 50. Since all SignalSolver backtests end up in either a buy (bullish) or a sell (bearish) state we calculate the sentiment by taking the ratio of bullish algorithms to total algorithms.
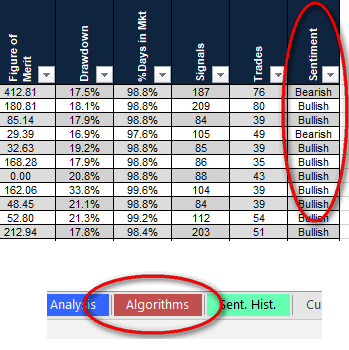
Each SignalSolver algorithm has a bullish or bearish sentiment
The sentiment for any given date may vary depending on the backtester settings and other factors.
Walk forward
The simulations calculate the sentiment for a single day (or week or month) at a time and then walk forward to the next trading day. On each cycle, the backtested algorithms are sorted by performance and the sentiment derived as described above. The included algorithms can change from day to day due to sorting. There may also be periodic changes to the algorithm set or their parameters in order to maintain the quality of the backtests.
As the simulation proceeds, one new OHLC data point is included and one old data point is excluded from the backtests.
Signalling thresholds
To trade using the sentiment indicator, we must somehow generate buy and sell signals and to do that we use simple threshold crossing. In the program you can define the buy and sell thresholds separately but for most of the simulations, we will set the buy threshold equal to the sell threshold, usually 50%. Crossing above 50% is a buy signal, crossing below 50% is a sell signal.
Occasionally we will show examples of simulations with a biased (non 50%) threshold. Occasionally we allow the program to optimize the thresholds periodically. We can even use inverted thresholds in which the buy will occur as the sentiment crosses below the threshold, and the sell above. When trading using SignalSolver Sentiment, its all about understanding and manipulating the thresholds.
Simulated trading using sentiment signals
Since we use Open High Low Close data and current price, we can simulate two types of trading. We can either
- Take a sentiment reading after the close and trade at the next open
- Take a sentiment reading just before the close and trade at the close
The first type of simulation will be slightly more accurate than the second, but if trading live you may have been able to fill orders at better or worse prices than the simulation indicates. Note that in type 1. simulations, the trading prices are always "out-of-sample", that is, the trading data points are outside of the backtest data. In type 2. simulations, the last price in the backtests is assumed to be the trading price, but in reality the trading price will still be out-of-band and could be slightly better or worse. But if you assume these errors are small and tend to cancel each other out, the simulations will end up being fairly accurate.
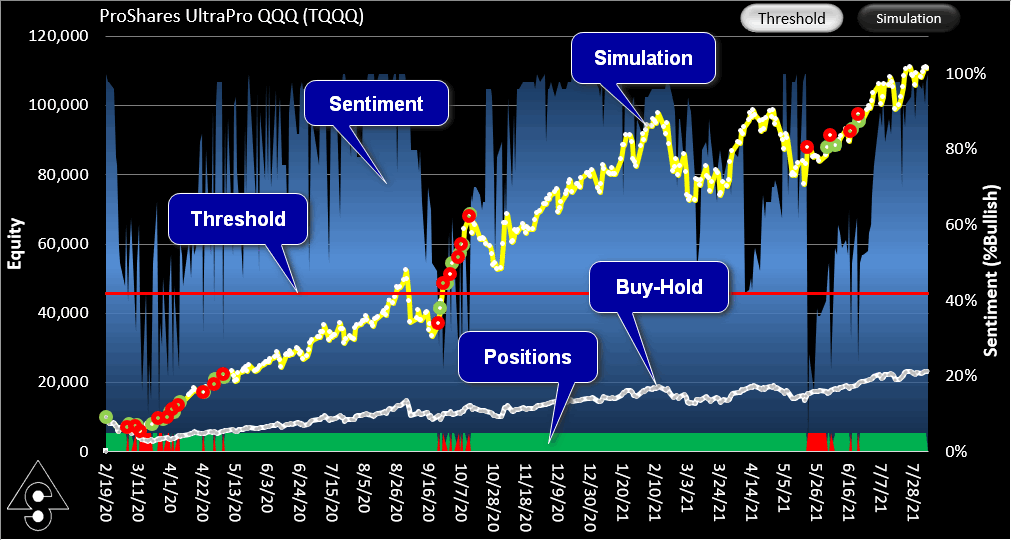
Equity Curves
There are two types of Equity Curves; Threshold view and Simulation view. They both show the result of investing $10,000.
Simulation View Equity Curve
Simulation view shows the result of simulating actual trading using sentiment with no prior knowledge about thresholds. It shows what actually would have happened had you adjusted the thresholds day to day (or had the program do it for you).
In the example below, the program automatically optimized the thresholds every 5 days, with buy and sell thresholds constrained to be equal. You can see that the thresholds converged on a value of 43%, ending up on a value of 42%. 
If you are curious to know what would have happened if you had started out with a 42% threshold, you can find out by looking at the Threshold view.
Threshold View Equity Curve
Threshold view shows the equity curve for a constant threshold. Below is the same TQQQ sentiment profile with a 42% threshold. It gives a better result but you would need a time machine to realize it. Simulation view shows what could readily have been realized if you had started cold on day one with no knowledge of threshold behavior. It's important to understand this distinction. But when you are making threshold decisions, Threshold view turns out to be very useful.
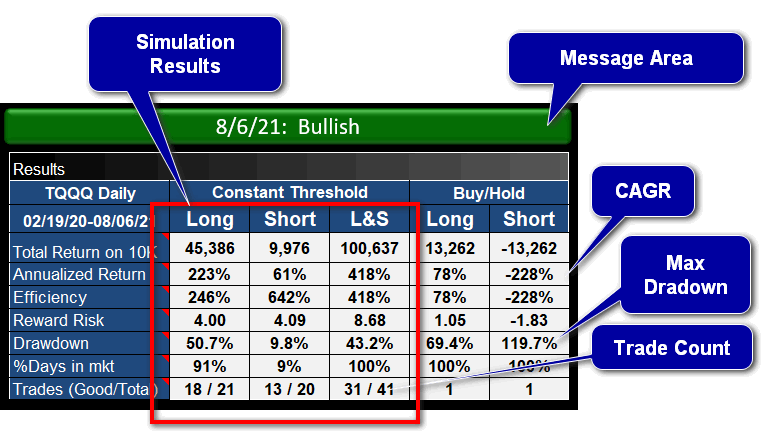
Performance tables
Below is shown the performance table for the Threshold view above. Again, these tables can be for Threshold or Simulation view, this one is for Constant Threshold. The message area informs the user what the sentiment is for the current date and if a change has occurred.
- Annualized Return is also known as the Compounded Annual Growth Rate (CAGR).
- Efficiency is relevant if you are out-of-the-market for some of the period. It is the Annualized Return if you had realized the return for the entire period.
- Reward-Risk is the Annualized Return divided by (Drawdown + 5%).
- Drawdown is the worst case loss if you had entered the strategy on a high and exited at a subsequent low.
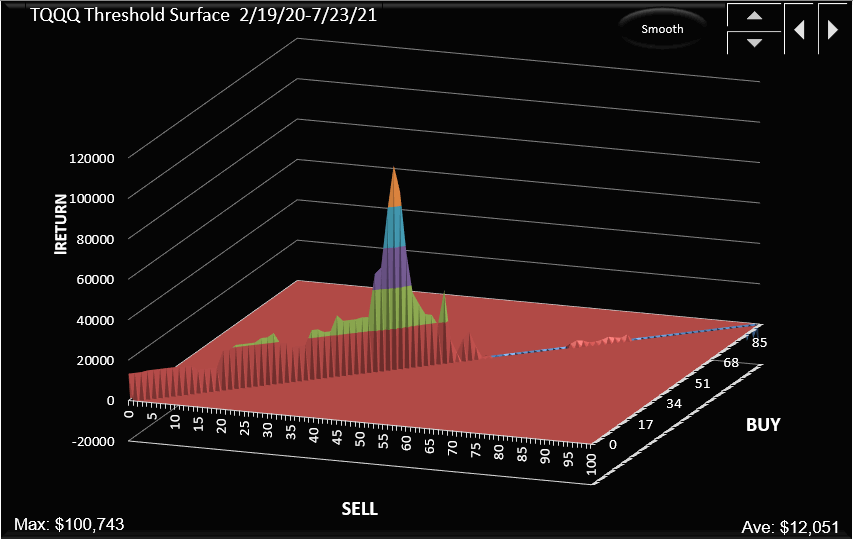
Threshold Surface
The Threshold Surface is a 3D chart showing the return for values of buy and sell threshold. Sometimes we show a partial surface, for example below we are showing only the surface for when the buy and sell thresholds are equal. You can see the peak at 42%.
We hope this explains how sentiment works and what the charts and tables in the postings represent.
You can read more about sentiment here